Spark vs Hadoop: ¿Cuál es el mejor marco de Big Data?
Esta publicación de blog habla sobre apache spark vs hadoop. Le dará una idea sobre cuál es el marco de Big Data adecuado para elegir en diferentes escenarios.

Esta publicación de blog habla sobre apache spark vs hadoop. Le dará una idea sobre cuál es el marco de Big Data adecuado para elegir en diferentes escenarios.
Este blog lo ayuda a comprender cómo instalar y configurar el complemento sbteclipse con instrucciones paso a paso para ejecutar la aplicación Scala en Eclipse IDE.
¡Esta publicación de blog explica por qué debe comenzar con Apache Spark después de Hadoop y por qué aprender Spark después de dominar hadoop puede hacer maravillas en su carrera!
Este tutorial de Apache Drill le brinda toda la información que necesita para comenzar con el motor de consulta Apache Drill, el uso con Hadoop, Big Data y Apache Spark.
Este blog de Spark Hadoop le dice todo lo que necesita saber sobre Apache Spark combineByKey. Encuentre el puntaje promedio por estudiante usando el método combineByKey.
Apache Falcon es una nueva plataforma de gestión de datos para el ecosistema Hadoop que simplifica el procesamiento y la gestión de feeds de incorporación en los clústeres de hadoop. Aprenda a configurarlo.
Este blog de Apache Spark explica los acumuladores Spark en detalle. Aprenda el uso del acumulador Spark con ejemplos. Los acumuladores de chispas son como contadores Hadoop Mapreduce.
Aprenda todo sobre Apache Flink y la configuración de un clúster de Flink en este blog. Flink admite el procesamiento por lotes y en tiempo real y es una tecnología de Big Data imprescindible para Big Data Analytics.
Esta publicación de blog analiza el almacenamiento en caché distribuido con variables de transmisión y lo ayuda a comenzar a distribuir de manera eficiente valores grandes en la programación de Spark.
Las certificaciones CCA y CCP de Cloudera han reemplazado a los exámenes CCDH y CCSHB. Este blog le dice todo lo que necesita saber sobre las nuevas certificaciones.
Esta publicación de blog analiza las transformaciones con estado con ventanas en Spark Streaming. Aprenda todo sobre el seguimiento de datos en lotes utilizando D-Streams de estado.
Esta publicación de blog analiza las transformaciones con estado en Spark Streaming. Aprenda todo sobre el seguimiento acumulativo y la mejora de habilidades para una carrera en Hadoop Spark.
Las tecnologías Hadoop y Big Data están revolucionando el análisis de la salud. Este blog de big data in health analiza cómo el análisis de big data puede mejorar la atención médica.
Esta publicación de blog sobre Hadoop Streaming es una guía paso a paso para aprender a escribir un programa Hadoop MapReduce en Python para procesar enormes cantidades de Big Data.
Este blog sobre Big Data Tutorial le brinda una descripción completa de Big Data, sus características, aplicaciones y desafíos con Big Data.
Este blog de tutoriales de HDFS lo ayudará a comprender HDFS o Hadoop Distributed File System y sus características. También explorará brevemente sus componentes principales.
En este tutorial de Splunk, comprenderá las diferencias entre Splunk, ELK y Sumo Logic, y determine cuál de estas herramientas le conviene más.
En este blog de casos de uso de Splunk, comprenderá cómo Domino's Pizza utilizó Splunk para obtener información sobre el comportamiento del consumidor y formular sus estrategias comerciales.
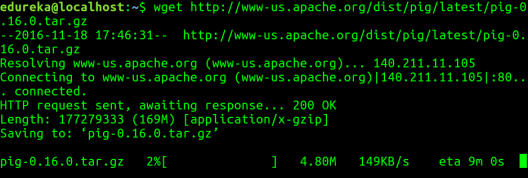
Este tutorial es una guía paso a paso para instalar el clúster de Hadoop y configurarlo en un solo nodo. Todos los pasos de instalación de Hadoop son para la máquina CentOS.
Este blog habla sobre los diversos comandos HDFS como fsck, copyFromLocal, expunge, cat, etc. que se utilizan para administrar el sistema de archivos Hadoop.